Review Occasionally, a database can be damaged or destroyed because of
Thủ Thuật Hướng dẫn Occasionally, a database can be damaged or destroyed because of Mới Nhất
Lê Hữu Kông đang tìm kiếm từ khóa Occasionally, a database can be damaged or destroyed because of được Update vào lúc : 2022-10-25 03:30:06 . Với phương châm chia sẻ Thủ Thuật về trong nội dung bài viết một cách Chi Tiết 2022. Nếu sau khi Read Post vẫn ko hiểu thì hoàn toàn có thể lại Comments ở cuối bài để Mình lý giải và hướng dẫn lại nha.System Recovery
Nội dung chính Show- System RecoveryMirrored DisksCrash Recovery: Notion of Correctness12.5 Road Map of AlgorithmsPage Model Crash Recovery AlgorithmsLog TruncationIntroductionIn the Beginning, There Was NetsaintObject
Model Crash Recovery14.3.1 Actions during Normal OperationDistributed DatabasesVII. Distributed Reliability ProtocolsReplicationWhat refers to the procedures that keep data current in a database?Which of the following is not an advantage of the database approach?What is the term for the process of comparing data with a set of rules or values to find out if the data is correct?Which of the following statements is not true about object oriented databases ODBC?
Philip A. Bernstein, Eric Newcomer, in Principles of Transaction Processing (Second Edition), 2009
Mirrored Disks
Media failures are a fairly serious problem, since as we will see, it can take a significant amount of time to recover from one. To avoid it, most TP systems use mirrored (or shadowed) disks. This means they use two physical disks for each logical disk that they need, so each disk has an up-to-date backup that can substitute for it if it fails. The mirroring is usually done in hardware, though operating systems also offer the feature in software. In either case, each write operation is sent to both physical disks, so the disks are always identical. Thus, a read can be serviced from either disk. If one disk fails, the other disk is still there to continue running until a new disk can be brought in to replace the failed one. This greatly reduces the chances of a truyền thông failure.
After one disk of a mirrored pair fails, a new disk must be initialized while the good disk is still functioning. Like mirroring itself, this is usually done in the hardware controller. The algorithm that accomplishes it usually works as follows: The algorithm scans the good disk and copies tracks, one by one, to the new disk. It has a temporary variable that identifies the track currently being copied. While it is copying that track, no updates are allowed to the track. Updates to tracks that already have been copied are written to both disks, since these tracks are already identical on both disks. Updates to tracks that have not yet been copied are written only to the good disk, since writing them to the new disk would be useless. This copying algorithm can run in the background while the good disk is handling the normal processing load.
Like restart, it is important that this mirror recovery procedure be as fast as possible. While it is going on, the good disk is a single point of failure. If it dies, then a truyền thông failure has occurred, which point the only hope is to load an old copy of the database and use a redo log to bring it up to date.
Even a fast mirror recovery procedure is intrusive. Mirror recovery does sequential I/O, whereas normal operation performs random I/O. So normal operation slows down mirror recovery and vice versa. Thus, the system needs enough spare disk bandwidth to do mirror recovery while giving satisfactory performance to users.
The failure of a log disk is especially problematic, since it affects all update transactions. There are many creative ways to minimize the effect of mirror recovery on writes to the log. For example, advanced disk-management software lets you set a low priority for repairing that mirror, but then mirror recovery is running much longer, during which time a second log disk failure would be a disaster. Another approach is to populate only a small fraction of the mirrored log disk, say 10%. This cuts the rebuild time and increases the random I/O rate during that rebuild. Or one can build a triple mirror; if a disk fails, wait until a slack time to rebuild the third drive of the mirror. Experienced database administrators build a synthetic load with peak log-write throughput and kill their log mirror to see if the system will continue to support the required service level agreement.
The choice of disk configuration will be greatly affected by the increasing availability of affordable solid state disks (SSDs). These disks perform sequential and random I/O about the same speed. Therefore, random I/O is less disruptive to mirror recovery than with magnetic disks. However, the cost per gigabyte of SSDs is considerably higher than for magnetic disks, and this gap is expected to continue going forward. It may therefore be desirable to use configurations that contain both SSDs and magnetic disks. It is too early to predict how the cost and performance tradeoffs will play out. However, it seems likely that it will continue to be challenging to design a storage configuration that meets a system’s service level agreement the lowest cost.
A related technology is RAID—redundant arrays of inexpensive disks. In RAID, an array of identical disks is built to function like one high-bandwidth disk (see Figure 7.26). A stripe is the set of disk blocks consisting of the ith block from each disk, where i is an integer between one and the number of blocks on a disk. If the disk block size is s and there are d disks in the RAID, then a stripe is, in effect, a logical block of size d×s. A RAID is high-bandwidth because the disks are read and written in parallel. That is, it reads or writes a stripe in about the same amount of time that one disk can read or write a single block.
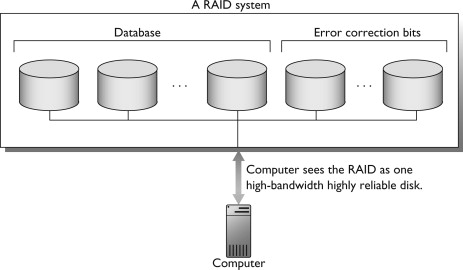
Figure 7.26. A Redundant Array of Inexpensive Disks (RAID). An array of disks built to function as one high-bandwidth disk. Using extra disks for error correction bits increases reliability.
Some RAID systems use extra disks in the array to store error correction bits, so they can tolerate the failure of one of the disks in the array without losing data. For example, an array of five disks could store data on four disks and parity bits on the fifth disk. Thus, the RAID can tolerate the loss of one disk without losing data. A write to any of disks 1 through 4 implies a write to disk 5. To avoid having disk 5 be a bottleneck, parity blocks can be distributed across the disks. For example, stripes 1, 6, and 11 store their parity block on disk 1; stripes 2, 7, and 12 store their parity block on disk 2; and so on.
The different RAID configurations are identified by numbers. Striped disks without parity are called RAID 0. Mirroring is called RAID 1 and can use more than two disk replicas. RAID 2 through 6 use parity in different configurations. RAID 10 is a RAID 0 configuration where each disk is actually a mirrored pair (i.e., RAID 1). This is called nested RAID, since it nests RAID 1 disks into a RAID 0 configuration.
Even if it is judged to be uneconomical to use mirrored disks or a RAID for the stable database, one should least use them for the log. Losing a portion of the log could be a disaster. Disaster is a technical term for an unrecoverable failure. There are two ways that a truyền thông failure of the log can be unrecoverable:
■After writing an uncommitted update to the stable database, the log may be the only place that has the before-image of that update, which is needed if the transaction aborts. If the tail of the log gets corrupted, it may be impossible to abort the transaction, ever.
■After committing a transaction, some of its after-images may be only in the log and not yet in the stable database. If the tail of the log gets corrupted and the system fails (losing the cache), then the committed after-image is lost forever.
In both cases, manual intervention and guesswork may be needed to recover from the failure. Therefore, it’s a good idea to put the log on a separate device and mirror it.
Even with mirrored disks, it is possible that both disks fail before the first failed disk is replaced. When configuring a system, there are some things one can do to reduce this possibility. First, one can try to minimize the amount of shared hardware between two mirrored disks. For example, if the disks share a single controller, and that controller starts scribbling garbage, both disks will be destroyed. Second, one can keep the disks in separate rooms or buildings, so that physical damage, such as a fire, does not destroy both disks. How far to go down these design paths depends on the cost of downtime if data becomes unavailable for awhile due to a truyền thông failure.
The general principle here is that protection against truyền thông failure requires redundancy. We need two copies of the log to ensure restart can run correctly if one log disk fails. We use mirrored disks or a RAID system that has built-in error correction to avoid requiring truyền thông recovery when a database disk fails. If the stable database is not mirrored and a disk fails, or if both mirrors fail, then yet another copy of the stable database—an archive copy—is needed in order to run truyền thông recovery.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B978155860623400007X
Crash Recovery: Notion of Correctness
Gerhard Weikum, Gottfried Vossen, in Transactional Information Systems, 2002
12.5 Road Map of Algorithms
The three logging rules of the previous section are fundamental invariants upon which every correct recovery algorithm relies. Some algorithms are, however, even more restrictive in terms of the relationships allowed between the cached database, the stable database, and the stable log. These additional invariants can be used to categorize a wide spectrum of crash recovery algorithms; in fact, all algorithms that have ever been proposed in the literature naturally fit into this categorization. The main idea is to distinguish algorithms by their need to perform undo and/or redo steps during restart. This leads to a taxonomy with four cases, as discussed next.
No-undo/ no-redo algorithms
1.
No-undo/no-redo algorithms: This class of algorithms maintains the invariant that the stable database contains exactly the actions of all committed transactions. Thus, during restart, neither undo nor redo recovery is needed; the “magic” of crash recovery is completely embedded in the additional work during normal operation. More formally, the invariant reads as follows: if an action p of transaction t in the history is in the stable database, then there must be a commit(t) action in the stable log, and if the stable log contains a commit (t) action of transaction t, then all data actions of transaction t must be present in the stable database.
To ensure the first condition of the invariant, a recovery algorithm has to guarantee that no page is ever flushed to the stable database if it contains any dirty updates made by uncommitted transactions. This property has been coined the “no-steal property” by Härder and Reuter (1983) because its most straightforward implementation is to build into the database cache manager that no such page can be “stolen” out of the cache as a replacement victim. For the second condition of the invariant, all pages that contain updates of a committed transaction must obviously be flushed the commit point. Because of these “forced” disk I/Os on the stable database, this property has been coined the “force property” by Harder and Reuter.
2.No-undo/with-redo algorithms: This class of algorithms maintains the invariant that the stable database contains no actions of an uncommitted transaction. More formally, this reads as follows: if an action a of transaction t in the history is in the stable database, then there must be a commit(t) action in the stable log. This is the first condition of the no-undo/no-redo invariant. Correspondingly, algorithms in this class are also known as no-steal algorithms. Restart after a crash potentially requires redo steps, but no undo recovery.
3.With-undo/no-redo algorithms: This class of algorithms maintains the invariant that the stable database contains all actions of committed transactions. More formally, this reads as follows: if there is a commit(t) action for a transaction t in the stable log, then all data actions of transaction t must be present in the stable database. This is the second condition of the no-undo/no-redo invariant. Correspondingly, algorithms in this class are also known as force algorithms. Restart after a crash potentially requires undo steps, but no redo recovery.
4.With-undo/with-redo algorithms: This class of algorithms does not maintain any special invariants other than the general logging rules of the previous section. Therefore, it is also known as the class of no-steal no-force algorithms. Restart after a crash potentially requires both undo and redo steps.
No-undo/ with-redo algorithms
With-undo/ no-redo algorithms
With-undo/ with-redo algorithms
Algorithms of the two no-undo categories are also referred to as deferred-update algorithms, since they have to postpone updates to the stable database until after the updates become committed. Such algorithms can be implemented in a variety of ways, based on different organizations of the stable log:
Deferred- update algorithms
With a no-steal database cache, the stable log can be implemented in its “standard form” as a sequential append-only file of log entries, where log entries need to capture only redo information, and various formats of log entries are possible.
In a shadowing approach, the stable log organizes updates of uncommitted transactions in pages such that these pages can be assigned to the (cached) database in an atomic manner. A simple and reasonably efficient implementation is to keep two versions of the database page addressing table, which is the table that translates page numbers into on-disk addresses such as extent or file numbers along with an offset. When performing (not yet committed) updates, new versions of the affected pages are created and registered in one version of the addressing table, while the other version of the addressing table is left unchanged. At commit time, the system switches from the unchanged, old version of the addressing table to the new version by atomically changing a stable “master pointer.” At this time, old page versions that are no longer needed are released by giving them back to the không lấy phí space management. The old page versions that temporarily coexist with the new ones are often referred to as shadow pages and the entire unchanged database as a shadow database. In addition to the new page versions, the stable log still needs to keep redo information in this approach, usually in a separate file, unless shadowing is coupled with a policy that forces the new page versions to disk before commit.
In a general versioning approach, the stable log file maintains versions of database objects, not necessarily in a page-oriented organization. These versions serve as a differential file to the database; the cached database and hence also the stable database are left unchanged until reaching a commit point. Updates of uncommitted transactions create new versions, and the commit of a transaction moves all versions that were created by the transaction into the cached database. Similar to shadowing, pointer switching techniques may be employed on a per-object basis for “installing” the new versions, or physical copying of versions if necessary. When commutativity properties of semantically rich database operations are exploited for higher concurrency, such operations may even have to be reexecuted to install their effects into the (cached) database. In this case, the differential file is more appropriately called an intention list. As with shadowing, the redo part of the stable log is still necessary in a versioning approach, unless new versions are forced to disk before commit.
Algorithms of the two with-undo categories, on the other hand, are commonly known as update-in-place algorithms, as updates are performed directly on the original database pages. The entire taxonomy of crash recovery algorithms discussed above is summarized in Figure 12.2.

Figure 12.2. Taxonomy of crash recovery algorithms.
Update-in-place algorithms
The case for with-undo/ with-redo algorithms
Our overriding performance goal of minimizing recovery time after a crash seems to make a strong case for the no-undo/no-redo algorithms as the method of choice. These algorithms achieve virtually instantaneous recovery by guaranteeing that the stable database is always in its correct state. However, focusing on recovery time alone would be too shortsighted. We also need to consider the extra work that the recovery algorithm incurs during normal operation. This is exactly the catch with the class of no-undo/no-redo algorithms. By and large, they come the expense of a substantial overhead during normal operation that may increase the execution cost per transaction by a factor of two or even higher. In other words, it reduces the achievable transaction throughput of a given server configuration by a factor of two or more.
The bad news on performance degradation needs to be explained in more detail. First consider the no-undo or deferred-update aspect of an algorithm. Its implementation is relatively inexpensive with a page-oriented shadowing approach. However, since such an algorithm is inherently restricted to installing complete pages commit time, it works correctly only in combination with page-granularity concurrency control. The detailed arguments for this important observation are essentially the same as in Chapter 11 on transaction recovery. Thus, this approach would rule out fine-grained concurrency control. We could resort to a general versioning approach, but there the commit of a transaction incurs substantial additional work, in the worst case, the copying of all new versions or even the reexecution of the transaction's update actions. This causes the factor-of-two degradation in terms of disk I/ O.
Now consider the no-redo aspect, which is even worse. The only way to avoid redo recovery is by flushing all modified pages the commit of a transaction—the force property. However, this would typically cause as many random disk I/Os on the stable database as the number of pages that were modified by the committing transaction. Compared to the sequential disk I/Os for appending the corresponding log entries to a stable log file, the extra cost for the no-redo guarantee may exceed a factor of 10. Therefore, the force policy of a no-redo algorithm is absolutely unacceptable in terms of performance.
The above discussion has brought up compelling arguments against both no-undo and no-redo algorithms, leaving us with the class of with-undo/withredo algorithms. This latter class is indeed the most general one in that it does not make any assumptions on the relationships between cached database, stable database, and stable log during normal operation (other than the three logging rules) and provides means for both undo and redo steps if these are necessary after a crash. As we will see in the course of the next chapter, there are effective ways to limit the amount of undo and redo work during a restart and hence bound the recovery time an acceptable level (on the order of one minute). In addition, the with-undo/with-redo algorithms provide high flexibility with regard to trading off an increased overhead during normal operation for faster restart. This can be achieved simply by intensifying the cache manager's activity of flushing dirty pages, without changing anything in the crash recovery algorithm.
For these reasons, the class of with-undo/with-redo algorithms is the only one that has found its way into commercial systems, and we have seen strong arguments that this choice is not incidental: the other classes are inherently inferior in significant aspects. Finally, a salient property of the with-undo/withredo algorithms is that they require relatively little (but subtle and carefully designed) changes when we want to move from the page model with pagegranularity concurrency control to the more general object model. For all these reasons, we restrict ourselves in the following chapters to the class of with-undo/with-redo algorithms.
Simplifications for sequential execution
Throughout this chapter, and the subsequent chapters, an inherent assumption is that transactions are executed concurrently during normal operation. This has consequences on crash recovery in that it rules out very simple solutions. Under certain conditions, however, it can make sense to completely abandon concurrency and execute transactions strictly sequentially. Such a radical solution is attractive for servers where all data fits into main memory and the throughput requirement for transactions can be met by a uniprocessor computer. In such a setting, concurrency is no longer needed to fully exploit the underlying hardware resources (disks and processors). Concurrent transaction scheduling may still be needed to cope with highly variable transaction lengths, for example, to prevent long transactions from monopolizing resources. However, there are certain applications, for example, in financial trading, where virtually all transactions are short. Then, under these premises, sequential transaction execution is perfectly acceptable, and crash recovery can be greatly simplified. In particular, a no-undo algorithm that atomically writes redo information to the stable log upon transaction commit could be implemented very easily and efficiently in such a setting. For the remainder of the book, however, we will not make such radical assumptions about excluding concurrency, but we will briefly come back to the issue of main-memory data servers in Chapter 15.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9781558605084500132
Page Model Crash Recovery Algorithms
Gerhard Weikum, Gottfried Vossen, in Transactional Information Systems, 2002
Log Truncation
Over time, the stable log collects a large number of log entries, some of which, we can infer, are no longer relevant regardless of when and how exactly the system crashes (as long as the stable database remains intact, which is our basic premise in this chapter). More specifically, we know that
a log entry for page p with sequence number s is no longer needed for redo recovery if the page sequence number of p in the stable database is equal to s or higher,
a log entry is needed for undo recovery only as long as the corresponding transaction is not yet completed.
Advancing the start of the stable log
All log entries that are no longer needed, neither for redo nor for undo, can be removed from the stable log as a form of garbage collection. However, it is not all easy to implement this garbage collection on a log file without interfering too much with the concurrent sequential I/Os for appending new log entries. Therefore, we restrict the scope of the garbage collection to remove only entire prefixes of the stable log. The implementation then simply requires advancing the pointer to the start of the stable log, which is kept in a separate master record on stable storage. The new start pointer is chosen to be the maximum LSN such that all log entries with smaller sequence numbers are obsolete. This point is computed by taking the minimum value over the following “lower bounds” for the still essential log entries:
SystemRedoLSN
For each cache resident and dirty page p, the sequence number of the oldest write action on p that was performed after the last flush action for p. This sequence number is called the redo (log) sequence number or RedoLSN of p. The minimum among the redo sequence numbers of the dirty cache pages is called the system redo sequence number or SystemRedoLSN.
The sequence number of the oldest write action that belongs to an active transaction. This sequence number is called the oldest undo (log) sequence number or OldestUndoLSN.
The oldest undo sequence number can be computed easily by remembering, in memory, the sequence numbers of the “begin” log entries for all currently active and, therefore, potential loser transactions. Determining the redo sequence number of a page requires a small and extremely low-overhead extension of the cache manager: it remembers, in its bookkeeping data structures in memory, the sequence number of the first write action on a page after that page has been fetched into the cache. When a page is flushed but remains in the cache, this remembered sequence number is reset to “undefined,” just as the page becomes “clean” again by the flush action. So this extension requires merely an additional sequence number field for each page frame of the cache.
Log truncation can occur any arbitrary point, but in practice it is good enough to invoke it only periodically, say, every five or ten minutes. A log truncation is in effect once the master record has been updated on stable storage. Subsequently, both the analysis pass and the redo pass are accelerated by scanning a shorter log. An inconvenient situation that can arise when a log truncation is attempted is the following. If the very first, that is, the very oldest, log entry in the stable log is still needed, then no truncation is possible, even if this first entry is immediately followed by a large number of obsolete entries. Such a “blocking” of the log truncation is unlikely to occur because of the oldest undo sequence number; this would only be possible if a transaction can remain active for the time frame of the entire stable log, typically hours. This is an unlikely situation, because truly long running activities such as workflows are not based on a single transaction. So the real troublemaker would be the oldest redo sequence number among the dirty pages in the cache. It is not very likely that it would be hours before a dirty page was flushed back to the stable database, but if the situation were so, there is a fairly simple remedy to enable the log truncation. At this point, a flush action should be enforced for the corresponding page, removing the page from the list of dirty pages. As a consequence, the minimum of the redo sequence numbers would then be advanced to the lowest redo sequence number among the remaining pages.
The overall procedure for log truncation is given by the pseudocode below.
Log truncation during normal operation

The correctness of the log truncation procedure follows directly from the garbage collection rule introduced in Section 12.4. A log truncation removes a subset of the log entries that can be eliminated according to the garbage collection rule. We do not consider a more formal statement or proof to be necessary here.
If the stable log contains full-write log entries, then log truncation can be even more aggressive. As a full-write contains all prior write actions on the same page, such a log entry renders all preceding log entries obsolete as far as the redo steps for that page are concerned. It is sufficient to keep only the most recent after image for each page that has been updated by a winner transaction. Furthermore, our previous consideration on flush actions is still valid: no after image needs to be kept when the page has been flushed to the stable database after its most recent winner update.
Log truncation for full-writes
Both considerations together yield the result that, as far as redo recovery is concerned, the stable log can be minimized to contain most one after image for each currently cache resident dirty page. Such a stable log can be implemented in an extremely compact manner: the name database safe has been proposed for it in the literature. Its size is on the same order as the server's database cache size, and if we keep the log entries for undo separately, the redo pass boils down to merely loading the database safe into the cache. Thus, we can obtain an extremely efficient restart with such an implementation.
The database safe approach is a special case of our general three-pass recovery algorithm, with redo logging being restricted to complete page after images. Managing the safe still requires continuous or periodic log truncation, based on tracking redo sequence numbers, as discussed above. The major drawback of the approach is that it seems to require a second stable log that holds before images for undo recovery. An alternative, where before images are held in the cache only (under the assumption of a no-steal cache replacement policy, see Chapter 12), has been worked out in the literature, and it is also possible to extend the method such that before images are appended to the safe as well so that a single stable log holds all physical log entries. In any case, however, using before images for undo recovery is inherently restricted to the page model where page-granularity concurrency control is required. Therefore, we do not further consider the special database safe approach in the rest of this chapter.
Combining physiological and physical log entries
Note that it is perfectly feasible for a log manager with physiological log entries to occasionally create full page after images and append them to the stable log, thus mixing physiological and physical log entries in the same log. This way the log manager can advance the RedoLSN of a critical page without depending on the cache manager to flush the page. This combined approach reconciles the advantages of physiological logging (lower log space consumption) with those of physical logging (more aggressive log truncation and faster redo) in a dynamically controllable manner. In the following, we will simply consider page after images as a special case of log entries, and will continue to focus on the more general notion of physiological log entries.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9781558605084500144
Introduction
Max Schubert, in Nagios 3 Enterprise Network Monitoring, 2008
In the Beginning, There Was Netsaint
Shortly after the first week of May 2002, Nagios, formerly known as Netsaint, started as a small project meant to tackle the then niche area of network monitoring. Nagios filled a huge need; commercial monitoring products the time were very expensive, and small office and startup datacenters needed solid system and network monitoring software that could be implemented without “breaking the bank.” At the time, many of us were used to compiling our own Linux kernels, and open source applications were not yet popular. Looking back it has been quite a change from Nagios 1.x to Nagios 3.x. In 2002, Nagios competed with products like What's up Gold, Big Brother, and other enhanced ping tools. During the 1.x days, release 1.2 became very stable and saw a vast increase in the Nagios user base. Ethan had a stable database backend that came with Nagios that let administrators persist Nagios data to MySQL or PostgreSQL. Many users loved having this database capability as a part of the core of Nagios, Nagios 2.x and NEB, Two Steps Forward, One Step Back (to Some).
Well into the 2.0 beta releases, many people stayed with release 1.2 as it met all the needs of its major user base that time. The 2.x line brought in new features that started to win over users in larger, “enterprise” organizations; this time, Nagios also started to gain traction the area of application-level monitoring. Ethan and several core developers added the Nagios Event Broker (NEB), an sự kiện-driven plug-in framework that allows developers to write C modules that register with the sự kiện broker to receive notification of a wide variety of Nagios events and then act based on those events. At the same time, the relational database persistence layer was removed from Nagios to make the distinction clear between core Nagios and add-ons/plug-ins and to keep Nagios as flexible as possible. NDO Utils, a NEB-based module for Nagios, filled the gap the core database persistence functionality once held. During the 2.x release cycle, NDO Utils matured and was adopted by the very popular NagVis visualization add-on to Nagios.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9781597492676000115
Object Model Crash Recovery
Gerhard Weikum, Gottfried Vossen, in Transactional Information Systems, 2002
14.3.1 Actions during Normal Operation
The simple recovery algorithm uses separate logs for the two levels of operations:
the L0 log contains physical or physiological undo/redo log entries for page writes on behalf of subtransactions,
the L1 log contains logical undo log entries (i.e., sufficient information about the inverse of a high-level operation) on behalf of transactions.
Both logs can be viewed simply as different instantiations of the log structures described in Chapter 13 for the page model. The L0 log is, in fact, absolutely identical to the page model log, with the only difference being that all its elements refer to subtransactions rather than transactions. In particular, all algorithms for the page model's redo-history recovery can be carried over without any changes. This also holds for the full spectrum of optimizations such as checkpointing, flush log entries, and CLEs that we discussed in Chapter 13. All we need to do is to replace transaction identifiers by subtransaction identifiers, but as far as the actual management of the L0 log is concerned, there is no difference. For clarity of the presentation, we will, however, use the terms “subbegin,” “subcommit,” and “subrollback” when referring to L0 log entries. During restart, the L0 recovery will redo all completed subtransactions—that is, those for which it finds a subcommit or subrollback log entry—and will undo all incomplete ones.
The L1 log can also be viewed as an instantiation of the log structure of Chapter 13. The difference, however, is that we will never perform any redo steps using this log, and the undo steps inferred from the log correspond to the invocation of inverse operations rather than page-oriented undo. The latter was occasionally referred to as compensation in Chapter 13, too, for example, when we introduced CLEs; in fact, there is no real conceptual difference between page-oriented low-level compensation and the high-level compensation that we need now for the L1 operations. Other than the specific content of log entries and their restriction to undo purposes, the L1 log is identical to a page model log. In particular, the technique of creating CLEs for undo steps and completing the undo of a transaction with a rollback log entry should be adopted here, too. Note that the fact that the L1 log merely serves the undo of transactions renders our repertoire of redo optimizations pointless; so there is no notion of checkpointing for the L1 log, for example.
Each of the two logs consists of a log buffer and a stable log. So we need to analyze what points one or both of the log buffers have to be forced for correctness:
Log force rules
The L0 log buffer needs to be forced whenever a dirty page is flushed to the stable database and the log buffer contains log entries for this page. This is the usual application of the undo log rule from Chapter 12, and not all specific to the object model. Note that without this forcing we would not be able to guarantee that incomplete subtransactions can be undone and would lose the subtransaction atomicity guarantee.
The L1 logbuffer needs to be forced upon the commit of a transaction. This is the usual application of the redo log rule from Chapter 12. As in the page model, it is the existence of the commit log entry on the stable log that really makes a transaction committed, and the transaction commit log entries belong to the transaction-oriented L1 level in the object model.
However, the existence of the commit log entry on the L1 log implies the promise that the transaction's effects can be redone. So this point, we need to ensure that the log entries for the L0 redo steps are on stable storage, too. This requires forcing the L0 log, too, and this writing of the L0 log buffer onto disk must precede the forcing of the L1 log buffer. So each commit of a transaction requires forcing both log buffers.
Once a subtransaction commits (or actually, subcommits) on the L0 log, it will later be redone by the L0 recovery if the server crashes. As long as it belongs to an incomplete transaction, however, we need to ensure that we have the necessary information to logically undo the transaction the L1 level. This consideration leads to the third and last log force rule: the L1 log buffer needs to be forced each time the L0 log buffer is written to the stable log, and the L1 forcing must precede the forcing of the L0 log. So we are guaranteed to have the proper inverse operation in our stable log for each subtransaction that survives the crash or will be redone level L0. Note, however, that we may find an inverse L1 operation on the stable log even if the corresponding subtransaction does not survive the crash and will not be redone either. This case may arise if the server fails after having forced the L1 log but before forcing the L0 log. We will discuss how to handle this situation in Section 14.3.2.
Note that the two requirements of forcing the L0 log before the L1 log and forcing the L1 log before the L0 log, stated in the second and third items above, are not contradictory, as they refer to different events. The first of the two orderings applies to transaction commits, and the second one to situations where the L0 log buffer is full or forced because of flushing a dirty page.
It is important to notice that the L0 log buffer does not need to be forced upon a subcommit. In this respect, the behavior of the L0 log differs from simply using a page model log for subtransactions as ACID units. Subtransactions need to be made atomic by the L0 logging, but unlike transactions, they do not have to be made persistent upon each subcommit. This point is important because the number of forced log I/Os is the most influential factor as far as the server's overhead during normal operation and potential throughput limitations are concerned. The good news about our approach for object model recovery is that, compared to the page model, this overhead is only moderately increased: we have essentially the same number of events that trigger the forcing of a log buffer, but the undo logging rule requires forcing both the L1 and the L0 log buffers sequentially, and the commit logging rule requires forcing the L0 and the L1 log buffers, again sequentially. We will show in Section 14.4 how this extra burden can also be eliminated in an enhanced version of the algorithm, by merging the log entries for both levels into a single log.
Given that the algorithmics for almost all action types fall out from the page model algorithms and log force rules discussed above, we merely give pseudocode for the L1 exec actions, which are the only actions during normal operation that are specific to the object model. Note that the log entry created for an L1 operation may sometimes be generated only the end of the corresponding subtransaction (i.e., after having performed all its underlying L0 read/write steps), the reason being that the inverse of such an operation may depend on the forward operation's return values and sometimes even on specific observations on internal state during the execution. In the latter case, the creation of an undo log entry would have to be integrated into the implementation of the ADT to which the operation belongs. In most cases, observing input parameters and return values should suffice, however. Finally, note that the log entry for an L1 exec action contains both a transaction identifier and a subtransaction identifier; the latter will be seen to be useful in the following subsection.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9781558605084500156
Distributed Databases
M. Tamer Özsu, in Encyclopedia of Information Systems, 2003
VII. Distributed Reliability Protocols
Two properties of transactions are maintained by reliability protocols: atomicity and durability. Atomicity requires that either all the operations of a transaction are executed or none of them are (all-or-nothing property). Thus, the set of operations contained in a transaction is treated as one atomic unit. Atomicity is maintained in the face of failures. Durability requires that the effects of successfully completed (i.e., committed) transactions endure subsequent failures.
The underlying issue addressed by reliability protocols is how the DBMS can continue to function properly in the face of various types of failures. In a distributed DBMS, four types of failures are possible: transaction, site (system), truyền thông (disk), and communication. Transactions can fail for a number of reasons: due to an error in the transaction caused by input data or by an error in the transaction code, or the detection of a present or potential deadlock. The usual approach to take in cases of transaction failure is to abort the transaction, resetting the database to its state prior to the start of the database.
Site (or system) failures are due to a hardware failure (e.g., processor, main memory, power supply) or a software failure (bugs in system code). The effect of system failures is the loss of main memory contents. Therefore, any updates to the parts of the database that are in the main memory buffers (also called volatile database) are lost as a result of system failures. However, the database that is stored in secondary storage (also called stable database) is safe and correct. To achieve this, DBMSs typically employ logging protocols, such as Write-Ahead Logging, which record changes to the database in system logs and move these log records and the volatile database pages to stable storage appropriate times. From the perspective of distributed transaction execution, site failures are important since the failed sites cannot participate in the execution of any transaction.
Media failures refer to the failure of secondary storage devices that store the stable database. Typically, these failures are addressed by introducing redundancy of storage devices and maintaining archival copies of the database. Media failures are frequently treated as problems local to one site and therefore are not specifically addressed in the reliability mechanisms of distributed DBMSs.
The three types of failures described above are common to both centralized and distributed DBMSs. Communication failures, on the other hand, are unique to distributed systems. There are a number of types of communication failures. The most common ones are errors in the messages, improperly ordered messages, lost (or undelivered) messages, and line failures. Generally, the first two of these are considered to be the responsibility of the computer network protocols and are not addressed by the distributed DBMS. The last two, on the other hand, have an impact on the distributed DBMS protocols and, therefore, need to be considered in the design of these protocols. If one site is expecting a message from another site and this message never arrives, this may be because (1) the message is lost, (2) the line(s) connecting the two sites may be broken, or (3) the site that is supposed to send the message may have failed. Thus, it is not always possible to distinguish between site failures and communication failures. The waiting site simply timeouts and has to assume that the other site is incommunicado. Distributed DBMS protocols have to giảm giá with this uncertainty. One drastic result of line failures may be network partitioning in which the sites form groups where communication within each group is possible but communication across groups is not. This is difficult to giảm giá with in the sense that it may not be possible to make the database available for access while the same time guaranteeing its consistency.
The enforcement of atomicity and durability requires the implementation of atomic commitment protocols and distributed recovery protocols. The most popular atomic commitment protocol is two-phase commit. The recoverability protocols are built on top of the local recovery protocols, which are dependent upon the supported mode of interaction (of the DBMS) with the operating system.
Two-phase commit (2PC) is a very simple and elegant protocol that ensures the atomic commitment of distributed transactions. It extends the effects of local atomic commit actions to distributed transactions by insisting that all sites involved in the execution of a distributed transaction agree to commit the transaction before its effects are made permanent (i.e., all sites terminate the transaction in the same manner). If all the sites agree to commit a transaction then all the actions of the distributed transaction take effect; if one of the sites declines to commit the operations that site, then all of the other sites are required to abort the transaction. Thus, the fundamental 2PC rule states: if even one site rejects to commit (which means it votes to abort) the transaction, the distributed transaction has to be aborted each site where it executes, and if all the sites vote to commit the transaction, the distributed transaction is committed each site where it executes.
The simple execution of the 2PC protocol is as follows (Fig. 3). There is a coordinator process the site where the distributed transaction originates, and participant processes all the other sites where the transaction executes. Initially, the coordinator sends a “prepare” message to all the participants each of which independently determines whether or not it can commit the transaction that site. Those that can commit send back a “vote-commit” message while those who are not able to commit send back a “vote-abort” message. Once a participant registers its vote, it cannot change it. The coordinator collects these messages and determines the fate of the transaction according to the 2PC rule. If the decision is to commit, the coordinator sends a “global-commit” message to all the participants; if the decision is to abort, it sends a “global-abort” message to those participants who had earlier voted to commit the transaction. No message needs to be sent to those participants who had originally voted to abort since they can assume, according to the 2PC rule, that the transaction is going to be eventually globally aborted. This is known as the “unilateral abort” option of the participants.

Figure 3. 2PC protocol actions.
There are two rounds of message exchanges between the coordinator and the participants; hence the name 2PC protocol. There are a number of variations of 2PC, such as the linear 2PC and distributed 2PC, that have not found much favor among distributed DBMS vendors. Two important variants of 2PC are the presumed abort 2PC and presumed commit 2PC. These are important because they reduce the message and I/O overhead of the protocols. Presumed abort protocol is included in the X/Open XA standard and has been adopted as part of the ISO standard for Open Distributed Processing.
One important characteristic of 2PG protocol is its blocking nature. Failures can occur during the commit process. As discussed above, the only way to detect these failures is by means of a timeout of the process waiting for a message. When this happens, the process (coordinator or participant) that timeouts follows a termination protocol to determine what to do with the transaction that was in the middle of the commit process. A nonblocking commit protocol is one whose termination protocol can determine what to do with a transaction in case of failures under any circumstance. In the case of 2PC, if a site failure occurs the coordinator site and one participant site while the coordinator is collecting votes from the participants, the remaining participants cannot determine the fate of the transaction among themselves, and they have to remain blocked until the coordinator or the failed participant recovers. During this period, the locks that are held by the transaction cannot be released, which reduces the availability of the database. There have been attempts to devise nonblocking commit protocols (e.g., three-phase commit), but the high overhead of these protocols has precluded their adoption.
The inverse of termination is recovery. When a failed site recovers from the failure, what actions does it have to take to recover the database that site to a consistent state? This is the domain of distributed recovery protocols. If each site can look its own log and decide what to do with the transaction, then the recovery protocol is said to be independent. For example, if the coordinator fails after it sends the “prepare” command and while waiting for the responses from the participants, upon recovery, it can determine from its log where it was in the process and can restart the commit process for the transaction from the beginning by sending the “prepare” message one more time. If the participants had already terminated the transaction, they can inform the coordinator. If they were blocked, they can now resend their earlier votes and resume the commit process. However, this is not always possible and the failed site has to ask others for the fate of the transaction.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B0122272404000460
Replication
Philip A. Bernstein, Eric Newcomer, in Principles of Transaction Processing (Second Edition), 2009
Caching
In a data sharing system two data manager processes can have a cached copy of the same data item. So they not only need to synchronize access using locks, but they also need to ensure they see each other’s cached updates. For example, in Figure 9.17 data managers S and S′ both have a cached copy of page P whose persistent copy resides in a shared database. S sets a lock on P the global lock manager, executes a transaction T1 that updates record r1 on page P, and then releases its lock on P. Now S′ sets a lock on P the global lock manager so that it can run a transaction T2 that updates a different record r2 on page P. To ensure that T1’s update to r1 does not get lost, it’s essential that T2 reads the copy of P that was updated by T1. This will work fine if S writes P to the shared database on behalf of T1 before T1 releases its lock on P.

Figure 9.17. A Data Sharing System. Page P is stored on disk. Processes S and S′ cache P in their private main memory.
Since a transaction needs to be durable, it would seem to be obvious that S must write P to the database before T1 commits. However, as we saw in Section 7.8, often this is not done. Instead, T1’s update to r1 might be written only to a log, without writing P itself to the database. In this case, S does not need to write P on behalf of each transaction, because later transactions that execute in S will access the cached copy of P and therefore are not in danger of losing earlier transactions’ updates. However, before S releases its lock on P the global lock manager, it needs to ensure that, if another data manager process locks P the global lock manager, it will access the latest copy of P in the shared database. For example, before releasing its lock on P, S can write P to the shared database. An alternative is for S to set a flag in the global lock for P that indicates it has the latest version of P in cache. When another data manager sets a lock on P, it sees that it should get the latest copy of P from S, not from stable storage.
Continuing the example, let’s suppose S writes P to the stable database and releases its global lock on P. Data manager S′ gets the global lock on P, reads P from the shared database, runs one or more transactions that update P, and eventually writes P back to the shared database and releases its global lock on P. Now, suppose S has another transaction that wants to access page P. So S sets a global lock on P. However, notice that S might still have a copy of P in its cache. If so, it will use its cached copy rather than reading it from the shared database. Obviously, this would be a mistake since S would ignore the updated value of P that was produced by transactions running in process S′. Therefore, even though S has a cached copy of P, it should invalidate this copy and reread P from the shared database.
What if no other process updated page P between the time S released its global lock on P and the time it set the lock again? In that case, it’s safe for S to use its cached copy of P. A simple bookkeeping technique can enable S to recognize this case. Each page header includes a version number. (An LSN could be used for this purpose; see Chapter 7.) The first time that a data manager updates a page P, it increments the version number. When it releases the global lock on P, it tells the lock manager the version number of the page. Although the lock has been released, the global lock manager retains the lock in its lock table with the associated version number. When a data manager sets a global lock on the page, the lock manager returns the page’s version number to the data manager. If the data manager has a cached copy of the page, it can compare this version number to that of its cached copy. If they’re the same, then it doesn’t need to reread the page from the shared database.
Using this version number technique, locks will remain in the lock manager even if no transaction is holding them. How does a lock disappear from the global lock manager, to avoid having the lock manager become cluttered with locks that are no longer being used? This could be done implicitly by a timer. If a lock is not owned by any data manager and has been unused for a period of time, then the lock can be deallocated. The time period should be long enough that any page that was unused in a data manager’s cache for that long is likely to have been deallocated. If the lock manager deallocates a lock too soon, then a data manager may request that lock while it still has the corresponding page in cache. In that case, since the lock manager is unable to tell the data manager the version number of the latest version of the page, the data manager needs to invalidate the cached copy of the page and reread it from stable storage.
Another approach to lock deallocation is to explicitly maintain a reference count of the number of data managers that have a cached copy of the page corresponding to each lock. When a data manager invalidates a cached page, it tells the lock manager to decrement the reference count. There is no urgency to have the lock manager do this decrement, so the data manager could save such calls in a batch and send them to the lock manager periodically.
Synchronizing shared pages between the caches of different data managers is one of the major costs in a data sharing system. One way to reduce this cost is to reduce the chance that a page needs to be accessed by two or more data managers. To take an extreme case, the database could be partitioned so that each data manager has exclusive access to one partition and each transaction only accesses data in one partition. Thus, each transaction uses the data manager that manages the partition needed by the transaction. Two data managers never need the same page, so cache synchronization doesn’t arise.
Of course, if all databases and transaction loads could be partitioned in this way, then the mechanism for dynamic cache synchronization would have little value, since each data manager can be assigned a partition statically. However, even if a perfect partitioning isn’t possible, an approximate partitioning may be within reach and serve the purpose. That is, each data manager is assigned a partition of the database, but it is allowed to access the rest of the database for the occasional transaction that needs data outside the partition. Similarly, transaction types are partitioned so that each transaction gets most, usually all, of its data from one data manager’s partition. Thus, cache synchronization is required only occasionally, since it is relatively unlikely that transactions running in different partitions happen to access the same data page.
For example, consider the debit-credit transaction workload of TPC-B, discussed in Section 1.5. The database could be partitioned by bank branch, so that each branch balance is accessed by most one data manager. By the nature of the application, tellers are partitioned by bank branch and each account has a home branch. So account records could be organized so that each page has account records with the same home branch. Each request takes an account ID, branch ID, and teller ID as input parameters. The branch ID parameter is used to send the request to that branch’s data manager. So the branch balance and teller balance for that branch are guaranteed to be in that data manager’s cache. Usually this branch ID for the request is the home branch of the account ID, since people do most of their banking their home branch. In this case, the account information is very unlikely to be in the cache of any other data manager. Occasionally, the account ID is not for the home branch. In this case, the data manager for the branch is accessing a page of accounts all of which are for another branch. There is a nonnegligible probability that this page is in the cache of the data manager of those accounts’ home branch. But it’s still a relatively low probability. Therefore, although cache synchronization for such cases does happen, it is relatively rare.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9781558606234000093
What refers to the procedures that keep data current in a database?
file or table maintenance. refers to procedures that keep data current (ex. adding records, modifying records, deleting records) Validation. compares data with a set of rules or values to determine if the data is correct (ex.Which of the following is not an advantage of the database approach?
Therefore, High acquisition costs are not the advantage of a database management system.What is the term for the process of comparing data with a set of rules or values to find out if the data is correct?
Data validation refers to the process of ensuring the accuracy and quality of data. It is implemented by building several checks into a system or report to ensure the logical consistency of input and stored data.Which of the following statements is not true about object oriented databases ODBC?
Compared with relational databases, which of the following is NOT true of object-oriented databases? -They allow programmers to reuse objects. Tải thêm tài liệu liên quan đến nội dung bài viết Occasionally, a database can be damaged or destroyed because of
Post a Comment