Mẹo Compares data with a set of rules or values to determine if the data meets certain criteria.
Kinh Nghiệm Hướng dẫn Compares data with a set of rules or values to determine if the data meets certain criteria. Mới Nhất
Bùi Ngọc Chi đang tìm kiếm từ khóa Compares data with a set of rules or values to determine if the data meets certain criteria. được Cập Nhật vào lúc : 2022-08-30 00:50:04 . Với phương châm chia sẻ Bí quyết về trong nội dung bài viết một cách Chi Tiết 2022. Nếu sau khi tham khảo Post vẫn ko hiểu thì hoàn toàn có thể lại Comment ở cuối bài để Ad lý giải và hướng dẫn lại nha.The Important Roles of Data Stewards
Nội dung chính- The Important Roles of Data StewardsSpecifying the Data Quality RulesImportant Roles of Data StewardsSpecifying the Data Quality RulesData Requirements Analysis9.6 SummaryData Stewardship Roles and ResponsibilitiesData QualityPractical AdviceData ProfilingKey ConceptsBusiness RulesEntity Identity Resolution16.8.2 Quality of the RecordsInspection, Monitoring, Auditing, and Tracking17.3 Data Quality Business RulesMetadata
and Data Standards10.9 SummarySumming It All UpFiguring Out What Metadata You’ve GotOther Techniques and ToolsStatus Selection CriteriaWhat is the database management system that compares data with a set of rules or values to find out if the data is correct?What is another term used for data dictionary?Which of the following is an item that contains data as well as the actions that read or process the data?Which of the following is a nonprocedural language that enables users and software developers to access data in a database?
David Plotkin, in Data Stewardship (Second Edition), 2022
Specifying the Data Quality Rules
Data quality rules serve as the starting point for inspecting what is actually in the database (data profiling). A Data Quality Rule consists of two parts:
•The business statement of the rule (“Business Data Quality Rule”). The business statement explains what quality means in business terms (see example). It may also state the business process to which the rule is applied and why the rule is important to the organization.
•The "Data Quality Rule Specification". The Data Quality Rule Specification explains what is considered “good quality” the physical database level. That is, it explains the physical datastore level, how to check the quality of the data. This is because data profiling examines the data in the database. The analysis portion of the data profiling effort then compares the database contents to the Data Quality Rule Specification.
For example, a rule for valid values of Marital Status Code for Customers might look like:
Business Data Quality Rule: The Marital Status Code may have values of Single, Married, Widowed, and Divorced. It may not be left blank. A value must be picked when entering a new customer. The values for Widowed and Divorced are tracked separately from Single because risk factors are sensitive to whether the customer was previously married and is not married anymore.
Data Quality Rule Specification: Customer.Mar_Stat_Cd may be “S,” “M,” “W,” or “D.” Blank is considered an invalid value.
The Data Quality Rule has to be highly specific as to what data element it applies to. In the previous example, it would have been necessary for the Data Quality Rule Specification to specify in which system (and possibly in which database) the table and column existed that were being tested. In a different system (with a different business process), the Data Quality Rule may look quite different, as in this example for Employees:
Business Data Quality Rule: The Marital Status Code may have values of Single and Married. It may not be left blank. A value must be picked when entering a new employee. Only Single and Married are needed as a check for benefits selected.
Data Quality Rule Specification: EmployeeDemographics.Marital_Cd may be “Sng,” or “Mrd.” Blank is considered an invalid value.
Another key point when specifying data quality rules is to specify all the rules that should exist. At the physical level, data quality rules break down into three main types, all of which can be important in evaluating the data quality:
•Simple Column Content Rules. These are considered “simple” because you only need to inspect the contents of a single column and check to see if the contents meet the rules. Samples of this type of rule include:
•Valid values, ranges, data types, patterns, and domains.
•Optional versus Mandatory (evaluates completeness).
•Reasonable distribution of values. For example, in a customer database, you would expect a fairly even distribution of birthdays; a much larger number of birthdays on a given day of the year probably indicates a problem.
•Cross-column Validation Rules. The rules require inspecting values in multiple columns (typically in a single row of a single table) to determine whether the data meets the quality rules. Samples of this type of rule include:
•Valid values that depend on other column values. An overall list of location codes might pass the Simple Column Content Rules, but only a smaller list of locations is valid if the Region Code is set to “West.”
•Optional becomes mandatory when other columns contain certain data. The Value of Collateral field may be optional, but if the loan type is “Mortgage,” a positive value must be filled into the Value of Collateral field.
•Mandatory becomes null when other columns contain certain data. The Writing Insurance Agent Name field might normally be mandatory, but if the Origination Point is “web” (indicating the customer applied for the policy online), the Writing Insurance Agent Name must then be blank.
•Cross-validation of content. Detects inconsistencies between values in different columns. One example cross validates the name of a city with the name of a state in an Address table. That is, Minneapolis is not in Wisconsin. Another example is that the “Maiden Name” column must be blank if the Gender is “Male.”
•Cross-table validation Rules (see Fig. 7.1): As the name suggests, these data quality rules check columns (and combinations of columns) across tables. Samples of this type of rule include:
•Mandatory presence of foreign key relationships. For example, if an Account must have a Customer, then the Account table must have a value in the Customer ID column that matches a value in the Customer ID column of the Customer table.
•Optional presence of foreign key relationships depending on other data. For example, if the Loan_Type is “Mortgage” in the Loan table, there must be a matching value for Loan_ID in the Collateral table. On the other hand, if the Loan_Type is “Unsecured,” then there must not be a matching value for Loan_ID in the Collateral table because “unsecured” means there is no collateral for the loan.
•Columns in different tables are consistent. For example, if the Collateral_Value column contains a value above a certain level, the Appraisal_Type must be “in person” because of the high value of the property.
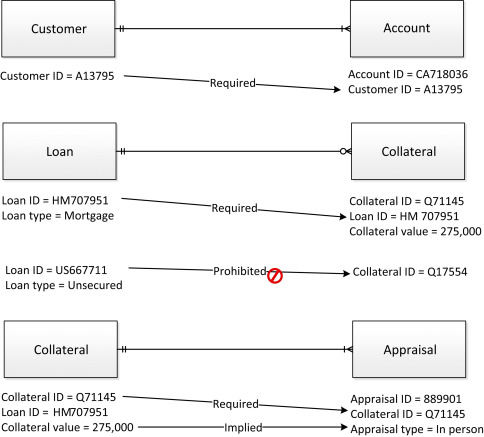
Figure 7.1. Cross-table validation rule relationships.
Note
The categories of these physical data quality rules look much like the data quality dimensions discussed previously in this chapter because those are the very dimensions being tested.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780128221327000073
Important Roles of Data Stewards
David Plotkin, in Data Stewardship, 2014
Specifying the Data Quality Rules
Data quality rules serve as the starting point for inspecting what is actually in the database (data profiling). A data quality rule consists of two parts:
■The business statement of the rule. The business statement explains what quality means in business terms (see following example). It may also state the business process to which the rule is applied and why the rule is important to the organization.
■The data quality rule specification. The data quality rule specification explains what is considered good quality the physical database level. This is because data profiling examines the data in the database. The analysis portion of the data profiling effort then compares the database contents to the data quality rule.
For example, a rule for valid values of marital status code for a customer might look like:
Business statement: The marital status code may have values of single, married, widowed, and divorced. It may not be left blank. A value must be picked when entering a new customer. The values for widowed and divorced are tracked separately from single because risk factors are sensitive to whether the customer was previously married and is not married anymore.
Data quality rule specification: “Customer.Mar_Stat_Cd” may be “S,” “M,” “W,” or “D.” Blank is considered an invalid value.
The data quality rule has to be very specific as to what data element it applies to. In the previous example, it would have been necessary to specify in which system (and possibly in which database) the table and column existed that were being tested. In a different system (with a different business process), the data quality rule may look quite different, as in this example for an employee:
Business statement: The marital status code may have values of single and married. It may not be left blank. A value must be picked when entering a new employee. Only single and married are needed as a check for benefits selected.
Data quality rule specification: “EmployeeDemographics.Marital_Cd” may be “Sng” or “Mrd.” Blank is considered an invalid value.
Another key point when specifying data quality rules is to specify all the rules that should exist. At the physical level, data quality rules break down into three main types, all of which can be important in evaluating the data quality:
■Simple-column content rules. These are considered “simple” because you only need to inspect the contents of a single column and check to see if the content meets the rules. Samples of this type of rule include:
❏Valid values, range, data type, pattern, and domain.
❏Optional versus mandatory (evaluates completeness).
❏Reasonable distribution of values. For example, in a customer database, you would expect a fairly even distribution of birthdays; a much larger number of birthdays on a given day of the year probably indicates a problem.
■Cross-column validation rules. The rules require inspecting values in multiple columns (typically in a single table) to determine whether the data meets the quality rules. Samples of this type of rule include:
❏Valid values that depend on other column values. An overall list of location codes might pass the simple-column content rules, but only a smaller list of locations is valid if, for example, the region code is set to “West.”
❏Optional becomes mandatory when other columns contain certain data. The Value of Collateral field may be optional, but if the loan type is “mortgage,” a positive value must be filled into the Value of Collateral field.
❏Mandatory becomes null when other columns contain certain data. The Writing Insurance Agent Name field might normally be mandatory, but if the Origination Point is “web” (indicating the customer applied for the policy online), the Writing Insurance Agent Name field must then be blank.
❏Cross-validation of content. An example cross-validates the name of a city with the name of a state in an address table—that is, Minneapolis is not in Wisconsin.
■Cross-table validation rules (seeFigure 7.1). As the name suggests, these data quality rules check columns (and combinations of columns) across tables. Samples of this type of rule include:
❏Mandatory presence of foreign-key relationships. For example, if an account must have a customer, then the account table must have value in the Customer ID column that matches a value in the Customer ID column of the Customer table.
❏Optional presence of foreign-key relationships depending on other data. For example, if the Loan_Type is “mortgage” in the Loan table, there must be a matching value for Loan_ID in the Collateral table. On the other hand, if the Loan_Type is “unsecured,” then there must not be a matching value for Loan_ID in the Collateral table because “unsecured” means there is no collateral for the loan.
❏Columns in different tables are consistent. For example, if the Collateral_Value column contains a value above a certain level, the Appraisal_Type must be “in person” because of the high value of the property.

Figure 7.1. Cross-table validation rule relationships.
Note
It is not a coincidence that the categories of these physical data quality rules look much like the data quality dimensions discussed earlier in this chapter.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780124103894000076
Data Requirements Analysis
David Loshin, in The Practitioner's Guide to Data Quality Improvement, 2011
9.6 Summary
The types of data quality rules that can be defined as a result of the requirements analysis process can be used for developing a collection of validation rules that are not only usable for proactive monitoring and establishment of a data quality service level agreement (as is discussed in chapter 13), but can also be integrated directly into any newly developed applications when there is an expectation that application will be used downstream. Integrating this data requirements analysis practice into the organization's system development life cycle (SDLC) will lead to improved control over the utility and quality of enterprise data assets.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780123737175000099
Data Stewardship Roles and Responsibilities
David Plotkin, in Data Stewardship, 2014
Data Quality
The data quality responsibilities include:
■Collect and document data quality rules and data quality issues from the project. Project discussions will often expose known issues with data quality as it relates to the intended usage. Alternatively, questions may arise about whether the quality of the data will support the intended usage. In such cases, the Project Data Steward should collect and document the data quality requirements that define what is expected of the data by the project.
■Evaluate the impact of the data quality issues on the project data usage and consult with the Data Governors or Data Stewards where appropriate. The consultation should discuss whether the perceived issues are real, and assess how difficult the data issues would be to fix. Data Stewards may suggest other sources of higher-quality data for project usage. The assessment will also feed into the decision on whether to expend the project work effort needed to profile the data in depth.
Practical Advice
A major data quality issue, coupled with a lack of an alternative data source, may have a significant impact on the project. In extreme cases, the project may actually fail due to poor data quality that was not discovered before the project started. In such cases, the project scope may need to be expanded to fix the data quality issue. The data quality fix may expand the scope of the project to the point where it is no longer economical or feasible. Clearly it is better to know that before the project has gotten underway. To put it succinctly, there is no sense beginning a project until some level of data inspection is conducted and the quality of the data is assessed.
■Consult with the Business Data Steward and project manager to determine if data should be profiled based on data quality rules and expectations collected on a project. Although the rules may not be well known (or known all) people who have requirements almost always have assumptions and expectations about what the data will look and act like. One of the nastiest surprises that can occur on a project is that data assumed to be fit for purpose is actually not of sufficient quality to serve the purposes of the project. The consultation with the Business Data Stewards and Technical Data Stewards serves to quantify the risk that the data quality is insufficient for the project’s purposes. The Project Data Steward can then work with the project manager to schedule a data profiling effort, adjusting the project schedule to allow for the extra time needed. As mentioned earlier, it is better to identify the need and profile the data prior to laying out the project schedule, as it can take a significant period of time to profile the data.
Note
Business Data Stewards should either already know the condition of the data or they should insist that the data be profiled. Making the Stewards accountable for the data also makes them accountable for demanding data profiling be performed where they feel it is warranted. Of course, if the project manager refuses to spend the time and expense, this must be recorded in the project risks to document the fact that the steward was ignored.
Note
It is possible to profile data without a tool, but tools are better. They can show you things that you might not be looking for, propose rules you might not know about, and store the results in a reusable form that can save time later. But the act of profiling is essentially one of comparison: what you have versus what you expect.
Data Profiling
Data profiling is the process of examining the contents of a database or other data source and comparing the contents against the data quality rules (rules that define what is considered “good quality” in the data) or discovering those rules. Ideally, any project that makes use of data should profile that data. This is especially true of projects that make use of data of questionable quality. Adding data profiling to a project that has not included it in the project plan can lead to significant delays. But not knowing what shape your data is in will lead to much bigger problems! Data profiling is a many-step process that requires collaboration between IT, business data analysts, data profiling tool experts, and the DGPO. These steps can include:
1.Determining what data to profile. Once the project has determined what business data it will need, that business data has to be mapped to its physical sources.
2.Preparing the profiling environment. Data profiling is rarely, if ever, performed on the production server using the operational data. Instead, the data must be migrated to a profiling environment. This involves setting up the environment (server, disk, and database engine), creating the data structures, and migrating the data itself. This is largely an IT task, and it is not uncommon for it to be a challenge to accomplish.
3.Running the profiling tool and storing the results. The data profiling tool expert performs this task, and if all goes well, this usually takes only a day or two, depending, of course, on the complexity and amount of the data.
4.Analysis of the results. This is the most manpower-intensive task, as the results of the profiling have to be reviewed with the appropriate Business Data Stewards. Business Data Stewards must determine whether any potential issues discovered by the tool are actually issues and work with the Technical Data Stewards and the project manager to formulate what it would take to remediate the issues. This typically requires close examination of the profiling results and a clear understanding of both the data quality rules and the characteristics of the actual data as captured by the profiling tool.
5.Document the results. The profiling results and analysis are documented in the tool, and may also need to be published in the project documentation.
As you can see, data profiling is somewhat involved and can take time. However, the time saved due to project delays usually outweighs the cost of the profiling. And as stated earlier, you either know the data is of high quality (probably because you have inspected it before) or it is simply foolish to proceed with the project without inspecting the data.
■Assist the data profiling efforts by performing data profiling tasks. If properly trained, Project Data Stewards can do some of the analysis and guide the work of others to ensure that standards are followed and the results are properly documented in the appropriate tools.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780124103894000039
Key Concepts
Danette McGilvray, in Executing Data Quality Projects (Second Edition), 2022
Business Rules
Ronald Ross, known as the “father of business rules,” describes a business rule as “a statement that defines or constrains some aspect of the business … [which is] intended to assert business structure, or to control or influence the behavior of the business.” He explains that “a real-world rule serves as a guide for conduct or action … and as a criterion for making judgments and decisions” (Ross, 2013, pgs. 34, 84).
For data quality, you must understand business rules and their implications for the constraints on data. See the Definition callout box for my definition of a business rule and related terms as they apply to data quality. Note that an authoritative principle means the rule is mandatory; a guideline means the rule is optional.
The relationships between business rules, business actions, and data quality rule specifications is seen in Table 3.7. In his book Business Rule Concepts (2013), Ronald Ross presents samples of business rules and informally categorizes each one according to the kind of guidance it provides. The first two columns are from Rońs book. The last two have been added to illustrate the business action that should take place and to provide an example of an associated data quality rule specification.
Table 3.7. Business Rules, Business Actions, and Data Quality Rule Specifications
Type of Business Rule**Example of Business Rule**Business ActionData Quality Rule SpecificationRestriction A customer must not place more than 3 rush orders charged to its credit account. A service rep checks customer’s credit account to determine whether number of rush orders placed exceeds 3. If yes, customer can only place a standard order. The rule is violated if: Order_Type = “Rush” and Account_Type = “Credit” and number of rush orders placed > 3. Guideline A customer with preferred status should have its orders filled immediately. A service rep checks customer status. If designated as preferred (“P”), order should be shipped within 12 hours of being placed. The guideline is violated if: Customer_Status = “P” and Ship_DateTime > Order_DateTime + 12 hours. Computation A customer’s annual order volume is always computed as total sales closed during the company’s fiscal year. Not applicable – based on automated calculations. The computation is correct if: Annual_Order_Volume = Total_Sales for all quarters in fiscal year. Inference A customer is always considered preferred if customer has placed more than 5 orders over $1,000. A service rep checks order history of customer when placing order to determine if customer is preferred. Preference is inferred when: Sum of 5 or more customer orders > $1,000. Timing An order must be assigned to an expeditor if shipped but not in-voiced within 72 hours. To ensure that the business transaction is finalized, service rep checks daily “Order Transaction” report and forwards to expeditor any orders shipped but not in-voiced within 72 hours. The rule is violated if: Ship_DateTime = 72 hours and invoice date = null and Expeditor_ID = null. Trigger “Send-advance-notice” must be performed for an order when the order is shipped. The “Send-advance-notice” is automatically generated when order is shipped. The rule is violated if: Send_Advance:Notice = null and Order_DateTime = not null. **Source: Ronald G. Ross, Business Rule Concepts: Getting to the Point of Knowledge, 4th Edition (Business Rule Solutions, LLC, 2013), p. 25. Used with permission.
Data is an output of a business process, and violations of data quality rules can mean that the process is not working properly – whether it is carried out manually by people or automated with technology. A violation of a data quality rule could also mean that the rule was incorrectly captured or misunderstood. Collect business rules to provide input for creating necessary data quality checks and analyzing the results of the assessments. The lack of well-documented and well-understood business rules often play a part in data quality problems.
 Definition
Definition
A Business Rule is an authoritative principle or guideline that describes business interactions and establishes rules for actions. It may also state the business process to which the rule is applied and why the rule is important to the organization. Business Action refers to action that should be taken if the business rule is followed, in business terms. The behavior of the resulting data can be articulated as requirements or data quality rules and then checked for compliance. Data quality rule specifications explain, the physical datastore level, how to check the quality of the data, which is an output of the adherence (or non-adherence) to the business rules and business actions.
– Danette McGilvray and David Plotkin
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780128180150000098
Entity Identity Resolution
David Loshin, in The Practitioner's Guide to Data Quality Improvement, 2011
16.8.2 Quality of the Records
Similarly, each record can be viewed within its own context. Data quality rules can be measured the record level of granularity (such as completeness of the data elements, consistency across data values, conformance to domain validation constraints, or other reasonableness directives), and these measures can provide a relative assessment of the quality of one record over the other. So when there is variation between the two records and the sources are of equal quality, assess the quality of the records, and that will provide the next level of guidance.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780123737175000166
Inspection, Monitoring, Auditing, and Tracking
David Loshin, in The Practitioner's Guide to Data Quality Improvement, 2011
17.3 Data Quality Business Rules
Data quality business rules are materialized as a by-product of two processes. The first is the data requirements analysis process (as described in chapter 9), in which the business data consumers are interviewed to identify how downstream applications depend on high quality data, and clarifying what is meant by “high quality.” The data requirements analysis process will result in a set of data quality assertions associated with dimensions of data quality. The second process providing data quality rules is the data quality assessment (chapter 11), in which empirical analyses using tools such as data profiling are used to identify potential anomalies that can be transformed into directed business rules for validation.
Either way, the intention is to use the business rules discovered to measure compliance. This implies that we have some reasonable capability to manage business rules metadata and have those rules be actionable in a proactive manner. Most data profiling tools provide a capability to document and manage business rules that can be directly incorporated into later profiling sessions, or even as invoked services to validate specific data values, records, or data sets on demand.
On the other hand, if there is no data profiling tool for managing data quality rules, there remain approaches for representing and managing data quality rules using logical expressions. Recall that chapter 9 reviewed the definition of different types of data rules reflecting these dimensions:
•Accuracy, which refers to the degree with which data values correctly reflect attributes of the “real-life” entities they are intended to model
•Completeness, which indicates that certain attributes should be assigned values in a data set
•Currency, which refers to the degree to which information is up-to-date with the corresponding real-world entities
•Consistency/reasonability, including assertions associated with expectations of consistency or reasonability of values, either in the context of existing data or over a time series
•Structural consistency, which refers to the consistency in the representation of similar attribute values, both within the same data set and across the data models associated with related tables
•Identifiability, which refers to the unique naming and representation of core conceptual objects and the ability to link data instances containing entity data together based on identifying attribute values
•Transformation, which describes how data values are modified for downstream use
As is shown in Table 17.2, in general, almost every high-level rule can be expressed as a condition and a consequent:
Table 17.2. Example Data Quality Business Rules
DimensionRule typeExample RepresentationPseudo-SQLAccuracy Domain membership rules specify that an attribute's value must be taken from a defined value domain (or reference table) Table.Data_element taken from named domain Select * from table where data_element not in domain Completeness A data element may not be missing a value Table.Data_element not null Select * from table where data_element is null Currency The data element's value has been refreshed within the specified time period Table.Data_element must be refreshed least once every time_period Select * from table where TIMESTAMP(data_element) within time_period Note that this will require timestamps as well as a coded method for accessing and verifying the time period duration Structural consistency The data attribute's value must conform to a specific data type, length, and pattern Table.Data_element must conform to pattern Select * from table where data_element not in_pattern(pattern) Note that this will require a coded method for parsing and verifying that the value matches the pattern Identifiability A set of attribute values can be used to uniquely identify any entity within the data set (Table.data_element1, Table.data_element2, Table.data_element3, Table.data_element4) form a unique identifier Join the table against itself with a join condition setting each of the set of attributes equal to itself; the result set will show records in which those attributes' values are duplicated Reasonableness The data element's value must conform to reasonable expectations Table.data_element must conform to expression Select * from table where NOT expression Transformation The data element's value is modified based on a defined function Table.data_element derived from expression Select * from table where data_element <> expression
If (condition) then (consequent)
Violators are expressed as those records where the condition is true and the consequent is false:
If (condition) and not (consequent)
Therefore, as long as the rule can be reduced into the if–then format, it can be expressed in any number of coded representations. For example, here is the transformation into SQL as a select:
Select * from table where (condition) and not (consequent)
For more information on the representation of data quality business rules, consider reading one of my previous books, “Enterprise Knowledge Management – The Data Quality Approach,” published by Morgan Kaufmann in 2000.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780123737175000178
Metadata and Data Standards
David Loshin, in The Practitioner's Guide to Data Quality Improvement, 2011
10.9 Summary
Data standards and metadata management provide a basis for harmonizing business rules, and consequently data quality rules from multiple (and probably variant) sources of data across the organization. Some general processes for data standards and metadata management have been articulated here; evaluating the specific needs within an organization can lead to the definition of concrete information and functional requirements. In turn, the data quality team should use these requirements to identify candidate metadata management tools that support the types of activities described in this chapter.
Lastly, the technology should not drive the process, but the other way around. Solid metadata management supports more than just data quality; a focused effort on standardizing the definitions, semantics, and structure of critical data elements can be leveraged when isolating data quality expectations for downstream information consumers. These processes also highlight the data elements that are likely candidates for continuous inspection and monitoring as described as part of the data quality service level agreement.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780123737175000105
Summing It All Up
David Plotkin, in Data Stewardship, 2014
Figuring Out What Metadata You’ve Got
A significant portion of what Business Data Stewards produce is metadata. Because metadata like definitions, data quality rules, and valid values are very useful to the people who use data, it is highly likely that many data and reporting analysts have been busily collecting this information for their own use and perhaps even sharing it with their coworkers. In some departments there may even be someone managing the metadata. And in IT, there may be a library of legacy system data dictionaries. These collections take all sorts of forms—spreadsheets, SharePoint lists, printed books, Access databases, and more. The Data Stewardship Council needs to locate these resources, gather them up, and, where appropriate, use the metadata as a starting point for defining the key business data elements.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780124103894000106
Other Techniques and Tools
Danette McGilvray, in Executing Data Quality Projects (Second Edition), 2022
Status Selection Criteria
For any individual test result, you must determine exactly how to assign status (e.g., if data quality rule 1 is less than 100% is it green? At what point are results red, meaning action is required?) I refer to this as Status Selection Criteria. How to determine the Status Selection Criteria is, once again, all about context. See Step 4.9 – Ranking and Prioritization for a technique that provides needed context and can be used to determine status selection criteria for metrics. Study Figure 6.9 for an example of how to capture results from a ranking and prioritization session as these apply to metrics.

Figure 6.9. Ranking and prioritization as input to metrics status selection criteria.
Next use what has been learned from the ranking session to set the final Status Selection Criteria. In Figure 6.9, let’s assume that the overall ranking for Patient Birthdate was High. Let’s use that information as input to Figure 6.10 – Example metrics status selection criteria. Since Patient Birthdate was an important identifier, the status selection criteria for green was set 100%. It was so important that anything less than 100% would move the status to red; therefore, a yellow status did not apply. You can see that there are two data quality rules for Patient Birthday that will be tested. If you ranked both Patient Birthdate tests together, the status selection criteria would be the same for both tests. Use the same line of thinking to work out the Status Selection Criteria for all the data quality tests.

Figure 6.10. Example metrics status selection criteria.
Note that the data quality rule examples in Figures 6.9 and 6.10 were all run using data profiling, the technique used in Step 3.3 – Data Integrity Fundamentals. Remember the data quality dimensions are categorized roughly by the approach used for assessing that dimension. That means when profiling the data, you will learn more about Patient Birthdate, Diagnostic Code, and other data fields than the two tests listed here (completeness and validity). You should decide which are the most important to monitor on-going. There is a cost to monitoring, so be thoughtful about what is worthwhile. Step 4.9 – Ranking and Prioritization helps here. In one project, the business initially prioritized a particular data field as very important. With the context provided during the ranking session, every line of business ranked it as low. You then must ask if the data field will provide enough value to continue monitoring it.
Read full chapter
URL: https://www.sciencedirect.com/science/article/pii/B9780128180150000037
What is the database management system that compares data with a set of rules or values to find out if the data is correct?
A consistency check tests the data in two or more associated fields to ensure that the relationship is logical and that the data is in the correct format. A DBMS uses the data dictionary to perform validation checks. A numeric check determines whether a number is within a specified range.What is another term used for data dictionary?
A Data Dictionary, also called a Data Definition Matrix, provides detailed information about the business data, such as standard definitions of data elements, their meanings, and allowable values.Which of the following is an item that contains data as well as the actions that read or process the data?
Chapter 10 - Database Management.Which of the following is a nonprocedural language that enables users and software developers to access data in a database?
GlossaryChapter 11.NETMicrosoft's set of technologies that allows almost any type of program to run on the Internet or an internal business network, as well as stand-alone computers and mobile devices.4GLFourth-generation language; nonprocedural language that enables users and programmers to access data in a database.Student Resource Glossary - Cengagewww.cengage.com › cgi-wadsworth › course_products_wpnull Tải thêm tài liệu liên quan đến nội dung bài viết Compares data with a set of rules or values to determine if the data meets certain criteria.
Post a Comment